Dan Bricklin's Web Site: www.bricklin.com
|
|
New Modes of Interaction: Some Implications of Microsoft Natal and Google Wave
New styles of interaction between people and computers, and how that will impact developers and designers.
|
|
Introduction
Every decade or so there has been a change in interaction styles between computers and their users. This change impacts both what the user sees and what the programmer needs to do when architecting an application. This change is brought about by innovations in both hardware and software. At first, mainly new applications are created using this new style, but as time goes on and the style becomes dominant, even older applications need to be re-implemented in the new style.
I believe that we are now at the start of such a change. The recent unveilings, within days of each other, of Google Wave (May 28, 2009) and Microsoft Natal (June 1, 2009), brought this home to me. This essay will explore what this new style of interaction will be like in light of the history of such steps in style, why I feel it is occurring, and when it will have an impact on various constituencies.
The Chronology of Adoption of New Styles of Interaction
Many technologies, when they are first developed, stay at a low level of adoption, with periodic isolated attempts to introduce them into new products. While they may be obviously "good" technologies, for various reasons -- be they hardware cost, quality of the user experience, or lack of demand for a change -- they don't catch on and become dominant. This can go on for many years, and usually does. A classic example is adoption of the computer mouse, first invented in the early 1960's , popularized in the mid-1980s by the Apple Macintosh, and not dominant as a means for controlling most desktop use of computing until the early 1990s.
I think it is helpful to see this as three main points in time, and depicted in this graph:
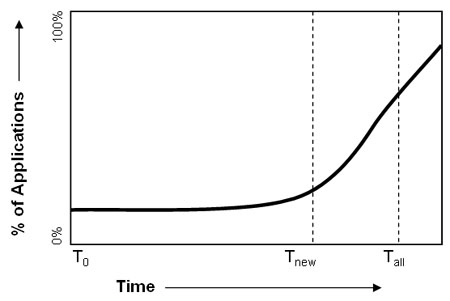 The first is T zero, when the style of interaction is first developed and deployed in a system of some sort. (Prior to that, the style may be "obvious" from a conceptual viewpoint, but not deployable in an actual product due to hardware limitations or lack of understanding how to implement it.) Over time, new products may try using the style once in a while, but at a very low penetration in the percent of new products. At some point, one or more of the products using the style really catches on, and, starting at a time I call time T new, the style becomes a requirement for most new applications. Anything implemented in a previous style would be viewed as old fashioned and lacking. Finally, at time T all even older, more mundane applications need to adopt the new style.
The application or applications, and perhaps the platform or hardware which makes them possible, that make time T new happen are often what are called "killer apps" -- they justify the entire system that runs them. However, for other applications to adopt this new style of interaction the style must be generalizable, and not just specific to the one enticing application. (This explanation is a little different than the classic "early, middle, and late adopter" graphs. It relates to producers and not consumers. A product category before time T new can be very successful with high penetration but without affecting any other software development.)
These dates are important to different parties. Developers of new applications, especially for general markets, such as ISVs (independent software developers), need to be able to switch their product designs to use the new style at T new. They can do it earlier, hoping to catch the beginning of a wave of adoption, and maybe even cause it to occur, but that has risk unless the style is a key element of the product. They can adopt later, but then they risk losing out to more "modern" applications from competitors.
Corporate and other developers of captive applications can wait until time T all. However, after that point they risk user unhappiness and perhaps training and other usability costs as their old-style applications become further and further from the mainstream.
Each style of interactivity affects not just what the user sees, and therefore the documentation, training, and marketing material, as well as perhaps the potential audience for the product, but it also affects the internal architecture of the computer programs that implement the applications and the way the data is stored and communicated. Switching to a new interaction style is not as simple as (to use an old automobile saying from the 1950s) just adding fins to the back of the car (that is, something cosmetic). Like in the automobile industry, where it can take years to switch to a new style of powertrain (which we are going through right now as electric engines are being added as a major propulsion component), switching interaction styles can take time, including learning how to design and implement applications that take advantage of it. Over time, software tools and frameworks are developed that make it easier and easier to implement applications in the new style, obsoleting some of the earlier ways of implementation. Being too early has a cost as well as being too late. Developing those tools on time can be a sales opportunity, too.
All of this makes it important to watch out for the signs that we are approaching a time T new, and to understand what it implies for product designs, both internal and external.
Historical Examples
Here are some examples of various styles of interaction that we have used with computers over the years. For each, I'll look at the general idea behind the style of interaction, how it affects computer program architecture, the data architecture related to it at the time, and a bit about the connectivity of the components of computing.
Early general purpose computers in the late 1940s and early 1950s that had a large adoption in businesses were based on punched cards. Typically, these cards were rectangular with 80 columns, each with a dozen vertical positions for holes to be punched. A "computer" system, such as the IBM 407, was "programmed" by inserting wires in a plug-board that connected reading hardware for each column to appropriate printing column hardware, sometimes with simple accumulation or logic (such as to skip printing a card if a column had a certain code).
The early digital computers of the 1950s and 1960s continued to use punched cards and printed output, this time with commands requiring holes punched in just the right columns instead of wires plugged into the right holes in a punchboard. Data was stored on removable media, either punched cards, magnetic tape reels, or rotating disk cartridges loaded onto the computers at the time the "job" was run, and then removed to make room for another. A common "interaction mode" was IBM JCL (Job Control Language), with commands like "//INPUT1 DD *". Programs read in input, processed the data record by record, and produced output, record by record, all in one long run without human intervention. Output was printouts and/or more magnetic tape, rotating storage, or cards.
In the 1970s the popular style of interaction was with printing timesharing terminals and command line input -- typing the right words in the right order, pressing Return, and then getting some printout on the same terminal or screen a few seconds or minutes later. The common interaction mode was like CompuServe and the UNIX Shell. We got client-to-one-server connectivity over regular telephone lines. The data was stored on the central computer and was always resident, available as part of a user's allocation of storage. Another style of interaction was "forms" based, with a terminal sending multiple fields of data to the host computer to process, much like a big command line. The output in that case was either sent to an attached printer or used as the next form to fill out or read on the screen, replacing the previous one.
The early personal computers of the 1980s had character-based video displays with instant response to each character key and function key press. The common interaction mode was like the original Lotus 1-2-3 or WordPerfect running under MS-DOS. Programs stored data locally on the computer for the user, usually mainly accessible only using the program that created it. Many worked on "documents" stored in individual files accessed through a simple hierarchical file system. Programs mainly waited for keystroke input, with commands interpreted based on various modes determined by previous keystrokes.
The late 1980s and early 1990s brought in GUI (Graphical User Interface) user interfaces with bitmapped displays and keyboard/mouse input and WYSIWYG command and control. The common interaction mode was like Microsoft Excel and Adobe Illustrator. Programs were written using an "event driven" organization. Programmers had to understand the concept of a hierarchy of containing "windows" that received these events. Instead of command names or dedicated function keys there was the concept of "focus" to determine which program code received the event notifications from the keyboard and mouse. It became expected for programs to have an "undo stack" so that the user could back up through operations. The old MS-DOS programs rarely had the ability to do undo, which usually requires program architecture designed with it in mind.
The applications in the mouse / GUI / keyboard world were very "one person at a desk"-centric. They had one 2-dimensional moving input (from the mouse), and multiple physical buttons for data or command modification (the mouse buttons and keyboard). Data, from the program viewpoint, was usually X/Y positions (something new from previous styles of interaction) or text. There were distinct, instantly recognizable events when commands and data were given. (The "double-click" command was different, as it was time-dependent and was usually a superset of the single-click command that starts it so as not to be ambiguous.) The presentation to the user was of a "desktop" with overlapping windows. The data continued to be document-oriented (word processing, spreadsheet, email, voicemail) or synchronous (chat, instant messaging, phone call) on one device at a time. Storage was either local to the machine or on a wired local area network operated by the same organization that owned the computers.
As time went on in the late 1990s and 2000s, we added sound output, and later sound input as a common component of applications. We got anything-to-anything connectivity using one system (the Internet) that could be wired and then wireless. A new style of interaction, using a browser, was developed. The browser was based on a GUI-style of interaction. The common interaction mode was Amazon.com and then GMail and Google Maps, basically variations on the standalone GUI applications, but with the data storage on a diverse collection of servers elsewhere and much of the processing being done on those servers, too. We got more and more bandwidth and lower and lower latency in the communications. We got highly animated bitmapped output, including video and animated transitions, making the models we were interacting with more and more real-world-looking but still the same basic architecture. The common interaction mode was YouTube. We got live video input. We went from email in a few seconds to chat to voice conversation-speed interactions. For this the common interaction mode was Skype.
New Technologies and Other Useful Background
All of the above should be well-known to most people who have been involved with computers over the last half century. In this section I want to give you enough background on technologies you might not know about, as well as list some that you probably do, so you'll know the reasons behind the predictions I make. You'll be able to make your own determinations about how "ready for prime time" these technologies are. I'll also refer back to specific examples that you can find in this source material.
The ideas behind much of what I'm going to present here are not new. They have appeared in various R&D and commercial products over the years. That's normal when you reach a time T new point. It is, though, the combination of features, the publicity they are getting, the exposure people will get to them, and other aspects that will be important in determining if these are signals that we are reaching an important threshold.
There are lots of links and videos associated with the first two technologies, Microsoft Natal and Google Wave. To best appreciate the rest of this essay, if you aren't very familiar with these two technologies you should at least look at the 3 minute and 40 second Natal concept video and the 10 minute simplified Google Wave video.
Microsoft Natal
The first set of technologies is found in Microsoft's Natal. This is a combination of hardware and software that Microsoft previewed for their XBox 360 gaming system. The short description, from a computer game viewpoint, is that they have developed a way of controlling the game without using a hand controller. Natal can be viewed as a response to the huge success of the Nintendo Wii. The Wii is operated using one or more wireless hand controllers with a few buttons. The Wii console can react to movement of the controllers in 3 dimensions, allowing you to "swing" a "tennis racket" or "bowl" using somewhat natural movements of the hands and arms, and not just by pressing buttons like with traditional game controllers.
With Natal, the gaming console can actually "watch" the gamer's whole body, and react to movement of the hands, arms, feet, head, and entire body. The system can detect the position of objects as well as what they look like and the sounds that they make. To understand the references I'll make to it, you should watch the 3 minute and 40 second "concept" video that Microsoft released with the announcement ("Project Natal for XBOX 360"):
You can find more information on the Natal website.
Apparently, Microsoft is making use of technology like that which it acquired from a company named 3DV Systems, along with a lot of other software and some hardware they are developing. Reportedly, 3DV Systems had been coming out with a $99 device that combined a normal webcam with another special camera that, instead of giving color and brightness information at each pixel like the webcam, gave an indication of the distance the image that would have been at that pixel was from the camera. (For example, points on close objects would be "brighter" than far ones.) The resolution was, I think, at least 200x200, if not closer to VGA, with an accuracy of 1-2 cm (when in a narrow distance range -- it's only 8-bits of distance information) and a frame rate of 60 frames per second. This is enough to be very responsive to body motion. See this product information: The old 3DV Systems website; a copy of their old brochure; Microsoft's Johnny Lee writing about it. 3DV Systems appears to have had a very experienced team, with the CTO and co-founder having been the technology founder of gastro-intestinal video capsule maker Given Imaging which makes a tiny camera you swallow to do endoscopy and which has been used by over a million patients.
The technology that 3DV Systems used is called a "Time of Flight Camera" (TOF) and refers to measuring the time it takes a pulse of infrared light to go from a light source next to the camera, bounce off of parts of what it is aimed at, and return to the camera. Like radar and sonar, you can determine distances this way, and with it being light, you can focus the returning rays on a camera sensor to give simultaneous readings for many points on the entire scene. You can read about Time of Flight Cameras on Wikipedia. There are multiple vendors making devices. Apparently this is very real and is based on semiconductor technology, so should improve with volume production and improvements in processes, just like webcams did, where they are now so inexpensive that you find them in the least expensive of computers (like cell phones, netbooks, and the OLPC XO) and where you see resolution and sensitivity keep improving at Moore's Law speed.
You can watch real people using a Microsoft prototype here to see how responsive they feel it is, and also here. Some demos of products from other companies show tracking and gestures for issuing commands: Demo of Orange Vallee's gesture-controlled TV, with Softkinetics technology and HITACHI Gesture operation TV. Here is a page from Softkinetics showing games: Softkinetic Videos.
Microsoft is also reportedly adding to the device an array of microphones that can locate a sound in space so it knows which of the people it sees is speaking.
Here is the general purpose technology I see when looking at these demos: Video cameras watching one or more people and the general scene in 3-D space, both Time-of-Flight and regular video. (Microsoft - and 3DV Systems - use both, which is an important combination.) It can recognize and act upon full body motion, including finger, hand, arm, etc., motion and facial expressions, coupled with basic voice recognition (with 3-D spatial sound info). You can learn the gestures by watching someone else -- such as on a video conference or together in a room using the same system. The user interface can provide different levels of coupling between you and what you see: It watches you for signals by yourself, or you "manipulate" things you see through an avatar that represents you on the screen and that mimics your motions, or you manipulate real or mimed objects in the real world that are reproduced on the screen or not. You can also capture images in real-space and then integrate that into the computer-space. In short, the technology lets the application developer use any mixture of gesture/motion/image recognition with video and still photo recording and voice recognition and sound recording.
The idea, and even implementation, of tracking arm motions and responding to voice commands is not new. The MIT Media Lab (then known as the Architecture Machine Group) showed demos of a Spatial Data Management System around 1980, the famous "Put that there" demo. Natal and other examples using today's technology, though, are bringing it to volume applications at consumer prices. We see that this is real and developing, not just a made up fantasy that is far off. Rumors are that Natal, as a real gaming platform from one of the top game console manufacturers, will be available in stores sometime in 2010. They have already shown prototypes of applications using Natal developed by outside software developers.
Even though Natal is initially being shown used for gaming, I see no reason why Microsoft won't make the technology available for personal computer use, too.
Google Wave
On May 28, 2009, Google previewed Google Wave, a product/platform/protocol that they are developing for release over the next year, and that is currently in limited beta test. There are many aspects of Wave, and it looks like there will be changes before it is released to the public (if they indeed do release it to the public at all). However, Wave brings together in one system and highlights many ideas that are reaching a critical mass regardless of what Google does with Wave. This is why it is worth looking at for our purposes here.
The main introduction to Google Wave is the hour and twenty minute presentation that they made at the announcement. You can watch that here (Google Wave Developer Preview at Google I/O 2009):
You can find shorter versions, such as this 10 minute version that chops up the full one and just shows the "highlights": "Google Wave presentation (shorten)". You can read a description by Dion Hinchcliffe on ZDNet and Google has provided lots of details, including the protocol specifications and API specifications.
Here is a characterization of Google Wave that looks to the issues we have been discussing:
A "Wave" is sort of like a threaded conversation on a traditional online discussion forum. Conceptually, a wave is stored as a single document on a single server. There are usually multiple waves on a Wave Server, and there may be any number of servers with their own waves, or copies of waves. Each wave has a single "home" server that keeps everything in order and is the definitive or "host" server for that wave. Associated with each wave is a list of the participants in that wave (those individuals or computer services that have access to it). Instead of just having some prose text in each node in the discussion, a wave is composed of messages (called "blips") with bundles of XML that represent the units of the conversation on the wave. These units can be text, images, video, or other data to be interpreted some way. The rendering and display of the data that makes up a wave is taken care of by code on wave user clients, usually running in a browser, which load the waves from a wave server (like an IMAP email client loads mail from an email server). The waves you have access to, in the samples shown, are presented in a manner that looks like an email client, with each wave taking the place of an email message shown in a separate window along its related thread of replies.
A key thing is that an ordered list of all of the steps in the creation of the wave is stored as part of the wave. Whenever someone makes changes or additions to a wave that they are viewing those changes are sent back to the home server, keystroke by keystroke, and made available to all other clients currently watching that wave. This makes it possible to have multiple people edit the wave and instantly have all the others who are looking at the wave see the changes. It also means that whenever you look at a wave it is always up to date. This is sort of like live, character-by-character chat merged with a wiki. The home server takes care of serializing the changes sent to it by clients making modifications, and then sending that new serialized stream of commands to any other system authorized to participate in that wave.
Like a wiki, an ordered list of all the changes is saved (along with an indication of who made them). In the demos they show how a person looking at a wave for the first time can drag a playback slider to the left and then "playback" the wave, watching its evolution over time step by step. (You can see this at about 1:40 in the short demo and 13:00 in the long one.)
Google is releasing the specification of Wave and how it works as open standards (it is built using some existing standards as well as some new ones) and is providing working code as open source. They have APIs for adding rendering components and "helper" plug-ins on the client as well as "robots" that can act as automatic participants in a wave conversation. They are encouraging other companies and individuals to create things using those APIs. They showed different implementations of the client and even an independently written server. (See 1:06:15 and 1:07:45-1:09:15 in the long video.)
Here is some of the general purpose technology I see implied by Wave and related systems:
Systems should allow multi-person collaboration on shared resources in real-time or asynchronously not in real-time, seamlessly handling both. All modification steps are kept and can be played back. There should be the ability to have ad hoc grouping of data and who has access. The shared resources need not all be on one system -- they may be on federated systems created by different parties. Robots / daemons should be able to participate along with any other participant in "conversations" in real-time. Use of the collaboration systems can occur as part of a normal face-to-face or remote conversation using voice and video and can be viewed as tools to facilitate the conversation, much as blackboards, overhead projectors, notepads, and napkins have acted in the past for face-to-face collaboration. Multiple devices must be supported, including handhelds. Systems should have open APIs so there can be UI extensions / re-implementations and integration with other systems.
Most of the concepts shown in Google Wave aren't new. Lotus Notes, for example, has been dealing with independent editing and ordering changes since it was first shown in 1989. Google's own Google Docs, Adobe's Buzzword and other Acrobat.com applications, and even the One Laptop Per Child's XO computer allow simultaneous multi-person editing. The combination, though, takes advantage of the current state of hardware, software, and user expectations.
Other Technologies
There are many other technologies and products that are having an influence on the change in user interaction styles. Here are some of them that should be familiar to most readers:
UI Implications
Looking at all of the above, here are some thoughts on how user interfaces will change.
I'll call what can be built with Microsoft Natal and related technologies a "Paying Attention User Interface". That would have the acronym PAUI, which can be pronounced "powwie" and would be appropriate since it is being used in video games where you strike things ("Pow!" See this January 2008 video of 3DV's ZCam boxing game.). (Calling it a "Wave" interface, as in waving at the computer, one of the gestures you can see in one of the videos, conflicts with Google Wave. Ironically, TOF cameras are also being looked at for use in automotive collision avoidance and airbag control systems, so it is also anti-powwie.)
PAUI can work with users close (right now at least one foot, I think, like in front of a monitor) or far (within a room), at any angle (compared to the fixed positions of a mouse or touch panel), and with multiple simultaneous participants. This is unlike touch panel technology which has issues with screen size and the need to have the touching be over the thing you are controlling and with the viewing angle (leading to arm fatigue in vertically mounted devices). PAUI can make use of multiple simultaneous moving inputs corresponding to a person's body parts (fingers, hands, eyes, lips, head, feet, etc.) each with gesture information. The TOF topographical information can be used to augment normal image capture information for facial and hand motion interpretation. (It's easier to remove a background for recognition when you know it's further away than the subject rather than just looking for 2-D image edge cues. Background replacement in video was an early target of 3DV Systems' technology -- no need for a blue or green background.) This gesture information, in 3 dimensions, lets you have an extensive set of commands and modifiers. However, the system needs to watch as commands are constructed -- unlike GUI and keyboard interfaces, specifying a command in a gesture-based system is not an instantaneous step function. Data input is continuous and may need to be coupled to visual feedback. Like some of the multi-touch systems, programs will have to be able to deal with multiple simultaneous users on the same system. Unlike touch systems, and like accelerometers, PAUI users don't have to touch the screen: This is important when you are controlling something you are watching and don't want your hand in the way or in awkward position, such as on a screen being shared by multiple people in the room.
The regular camera can be used for normal image capture for image and video data, as shown in the Natal video when the physical skateboard is used as a model for the virtual one. PAUI, as demoed by Microsoft, can also use sound input with position detection, and sound input for adding to video for communication. Just as the mouse in GUI was used in conjunction with the older keyboard technology, PAUI can interface with mouse, keyboard, voice, as well as touchscreen hardware and accelerometers in handheld computers or controllers.
A nice thing, in terms of durability and use in different environments, is that there are no moving parts except the user. (Remember how the computer mouse was improved when it went from using a moving ball to just a solid-state optical sensor.) Advances can follow Moore's Law since improvements can be chip-based and not mechanical based. Since PAUI only needs one or two inexpensive small cameras and an infrared light (which may all be right next to each other and where the sensor is the main issue), it can eventually fit on any size system, from handheld to wall sized.
As the demos show, the sensors are fast enough (some inexpensive current units track 3-D movement at 100 frames per second) and granular enough if the CPU is fast enough, for fine, responsive control. Like a mouse and unlike directly touching the screen, the movement on the screen of something does not have to correspond millimeter by millimeter to your finger movement.
Voice recognition, when used for commands and for simple data in restricted vocabularies, can use context to aid accuracy. Sound-source position detection can aid in determining which of multiple people to follow for interpreting commands.
The new graphical styles that we are seeing with new systems and that will fit well with PAUI make use of more than just overlapping and basic position/size transformations tied to one moving cursor. You will expect more morphing, transparency, animation, apparent direct connection to complex finger/hand/arm movements and more Newtonian physics-like behaviors. This is much more complex than the normal GUI systems.
Google Wave symbolizes some other changes.
Old computer use was either document oriented (word processing, spreadsheet, email, voicemail), or synchronous (chat, IM, phone call) on one device at a time. The new is a fluid mixture, with each person's contributions being tagged with their identity and often other metadata. The old involved individual's spaces, the new includes fluidly shared spaces. In the old we passed around copies. In the new we all work on a single copy. There is a strong influence of the concepts we find in wikis. Two quotes from wiki inventor Ward Cunningham (from a podcast interview that appears in my book): "If you can read it you are close to being able to write it," and "The organization of the page is not the chronology of its creation," to which I'd add: But the chronology of creation is accessible and navigable in a useful way. The old organization was hierarchical and identifier/address-based; the new makes additional use of tags and searching, and the link space is broad. The new has freeform assembly of multi-type objects (text, images, video, widgets, links). Standards and interoperability are key. Multi-device input and output will be used as appropriate, including handheld, laptop/desktop, and wall, all feeding into and retrieving from shared spaces.
People expect to see the status of "now". That includes merged flows with data that can be merged and mashed up with unforeseen other data. We have seen the success of RSS in meeting needs like this.
So, imagine using a system in a meeting or conference call that is PAUI controlled, with Google Wave-like recording and playback, and computer assistance. This should help collaboration, and therefore has implications for productivity improvements.
Systems that are used in collaboration have a strong social component which influences their design and if done right can result in great power and if done wrong can result in them being abandoned. In discussions I've had about this with John Sviokla he points out that "social" is a driving force and that "social beats out the mechanical." This mirrors some of what I point out in my "What will people pay for?" essay and is a major point in my book. John also feels that using such tools will have an affect on how we work and how we think. He likens it to "ingestion of tools": You are what you eat/use. John points out that the view I present is one of a "new architecture of time." Spreadsheets like VisiCalc and Lotus 1-2-3, "killer apps" of the early PC era with instant recalculation and easy model construction, brought in a new attention to actually looking at numbers and doing scenario, what-if planning. He sees the potential for a "1-2-3 of time" in these new tools. Some of the characteristics of Google Wave show how we might "reinvent the synchronicity of time."
Application Architecture Implications
For programmers and system designers, the changes implied by these new interaction styles will have implications. The way applications are architected, the tools we use to construct them, the APIs we need, and more will change.
We saw such a step from the "character based" world (e.g., MSDOS, Lotus 1-2-3) to the GUI world. In the GUI world your applications needed to add undo (which could mandate a change in the design of internal data structure, command executions, and more). Your applications need 2-D windows and the concept of an item with the focus. In the GUI world, there were simple events that drove most applications based on X/Y positioning and a container hierarchy usually visible on the screen. This replaced the older need to just listen to a stream of keyboard events.
APIs like that supported by the Apple Macintosh, Microsoft Windows, and other systems were developed to handle windowing systems and mouse/keyboard interactions. Frameworks were developed and supported by various development tools to make it easier to write to these APIs and maintain all of the data structures and routines that they required.
In the new world I paint here, applications will more commonly need to support synchronous and asynchronous multi-user editing and reconciliation. There will possibly be multiple points of focus, plus unscheduled collaborative user / robot changes to what is being displayed. For many applications, this will be quite complex and, like undo before it, require a rethinking and rearchitecting of applications, even ones as simple as basic text editing. Applications will now need to support visual playback and more extensive use of animation as a means to show changes. For each type of data being worked with, new presentation methods will need to be developed, including the presentation of changes by both the user and other entities and what "collaborative editing" looks like in the same room and remotely.
In gesture-based interfaces, there are many issues with determining the target of a command indicated by the gesture, as well as determining which gesture is being made. The determination of how to interpret a gesture is often very context dependent, and that context is often very dependent on exactly which data is being shown on the screen. Robert Carr of GO Corporation demonstrated some of the complexity there back in the early 1990s when he would show how a "circle" gesture made with a pen on the computer screen could indicate a "zero", the letter "O", a drawn circle, and selection of various sorts. (You can watch a copy of a video of Robert demonstrating Penpoint in 1991 that I posted on the web.) The applications programs sometimes have to participate in the recognition process to help with disambiguation. To determine the target of a gesture takes more than a simple contained-window hierarchy. You often need more sophisticated algorithms. This is especially true for PAUI with complex gestures. The "hit" area for where you can make (or aim) the gesture are often larger than the logical target on the screen and often overlap with other potential such areas for other parts of an application (or other applications). With a mouse (and even a pen, especially when it can control a "cursor" when not yet touching the screen, as most Tablet PC systems allow) you can easily control selection to almost the pixel level of resolution. Touch, with the varying sizes of human fingers, and "waving" interfaces need different layouts and techniques for indicating and enabling control areas on the screen. New methods of feedback need to be used, including during and after the fact animations, sounds, and tactile sensations.
Character-based user interfaces usually needed to be made speedy enough to keep up with the repeat rate of the keyboard, or at least the speed of typing. GUI systems needed to keep up with the speed of mouse movements. The new systems will need to keep up with multiple simultaneous gestures as well as real-time voice/video and streams of remote commands, showing the flow of changes in a coherent, comprehendible manner.
The needs of accessibility (for people with differing levels of ability to use various means of interfacing with a computer), multiple-style devices (including at least handheld, desk, and wall mounted ones), and plug-in and mashup friendly frameworks have additional implications for program architecture. Application program interfaces at many different levels, as well as Open and well-documented data interchange standards, will be needed. There will pretty certainly need to be more than one way to accomplish many tasks in the interface. Because of the needs of gestures and keeping track of multiple edit history the APIs will probably be different than existing ones. This all fits nicely with the "assemble components" design of the Wave display of a wave. However, there will be challenges with reconciling this with the desire to have access to the expressiveness sometimes needed through fine control of data placement on the screen and other aspects of the display.
For all of the above, there will probably be a widespread need to rearchitect existing ways of doing things and develop and/or learn new approaches for new applications. This will also lead to new frameworks for applying those approaches and perhaps new tools and languages to best help express them.
When?
The big question is when will there be a mandate for most new applications to use these new interface styles and when will old ones need to start being converted over.
I see pressure building because of the widespread acceptance of some of these concepts in popular devices and systems. Many of the concepts are things users have wanted to do for many years but that were too expensive or clunky in the past. We now have consumer-volume and consumer accepted examples of many of these technologies. Enough time has passed since the early versions to make this not new and just a flash in the pan. The huge success of the Apple iPhone and Nintendo Wii shows how much pressure there will be on other developers to follow suit when an interface style "clicks" with the general public.
I believe that requiring a touch (including gesture based touch) interface on new applications is starting now in many cases. It is required for handheld, and soon (in 1-2 years) will be required for new pad sized, wall sized, and maybe desktop systems. Corporate applications targeted to these new devices will need to use the new interfaces, and existing applications will have a few years more to migrate.
The ability to handle multiple simultaneous or dispersed editors, with playback, rollback, etc., is becoming more and more required for various types of new systems. Wiki-related system, such as from Socialtext (a company I am working with), have had variations on revision history and rollback on shared editing, including simple comparisons between versions, for years and that is becoming very common. New designs from now on, especially once Google Wave and Adobe Acrobat.com get in wider use, will have to explain why they don't have simultaneous editing or playback. I see it being required on new systems in 2-4 years, and needing to be retrofitted on old systems perhaps in 8-10.
I can see PAUI being a requirement in the gaming area in a year or two. If you include a moving controller (like the Wii), then it is already a requirement. In normal computing, I can see it becoming the dominant new interface in 4-8 years, but only 2-4 years for being common in high-end video conferencing.
The speed of adoption of PAUI and gesture interfaces will be somewhat under control of major operating system and hardware manufacturers like Microsoft and Apple. By making it the main way that users control their systems and major applications provided by those companies they can set the dates when others have to follow. By opening up the capabilities of their systems for others to exploit, and by making add-on hardware that can be used on other systems, they can also increase experimentation and hasten the day when they become ubiquitous.
With the varieties of hardware and new software to exploit them that we see here, it looks like the whole area may become a patent thicket which could slow down widespread adoption. The scenarios I paint have a need for openness and the right to mashup and experiment, and for there to be common standards. This can be in conflict with the world of patents and the specific agendas of individual companies that hold them, though that doesn't need to be the way it will work out. We'll see. In any case, it will be exciting and the possibilities look wonderful.
Let us look a little closer at Microsoft, since they are most involved in Natal.
Some of Microsoft's strengths are: They have a history of long-term R&D in gestural interfaces. They are a major player in the add-on user interface and other hardware markets, with a presence in mouse, gaming, Microsoft Surface, and, to a lesser extent, music player worlds. They released their first mouse in the early days of PC mouse-based computing, and even got one of their very first patents with one (patent 4,866,602) relating to getting power for the mouse from the serial adapter where you plugged it in instead of needing a separate power supply, thereby lowering the barrier to adding one to your existing computer. They have done research on life-recording and meeting audio and video. They have the R&D they did and that they purchased relating to Natal. They have a tools/platform-maker mentality, relationships with hardware manufacturers and software developers, and have a long history of participation in standards.
I think that they are in a great position to lead the industry in a new direction, and even profit handsomely whether or not Windows is the only platform to exploit it. Unfortunately, with respect to this and Wave-related things, they seem to have a desire to defend and backwards-support Office and Windows. They have an apparent ambivalence towards Open relationships which could hamper wide acceptance of standards. I believe that they have great opportunities here, if they rise to the occasion.
I hope this essay has given you food for thought. These are important areas and it will take time for developers to figure out the right ways to go, the best ways and time to get there, and all of the implications and possibilities. We have an incredible opportunity for moving the human use of computing a quantum step forward.
- Dan Bricklin, July 7, 2009
This essay grew out of a session I led at a conference (see my blog post). We ended up with a wonderful discussion about what these systems may be like to use and the issues we'd run into. I decided to do this topic because I was already in the mindset of looking at the evolution of new technology at the time, having just published a new book, Bricklin on Technology, relating to people and technology, how that technology is developed, and how it evolves.
- Dan Bricklin, July 7, 2009
|
|
|
© Copyright 1999-2018 by Daniel Bricklin
All Rights Reserved.
|